

지난 포스팅에서 스파크에 대한 기본 구조를 알아보았습니다. 이번 포스팅에서는 좀더 깊게 들어가서 스파크의 아키텍처를 알아보고 어떻게 동작되는지 알아보겠습니다.
1. 스파크 아키텍처
1.1 스파크 아키텍처 기본 구성
스파크 아키텍처는 크게 아래와같이 3가지로 구성되어 있습니다.
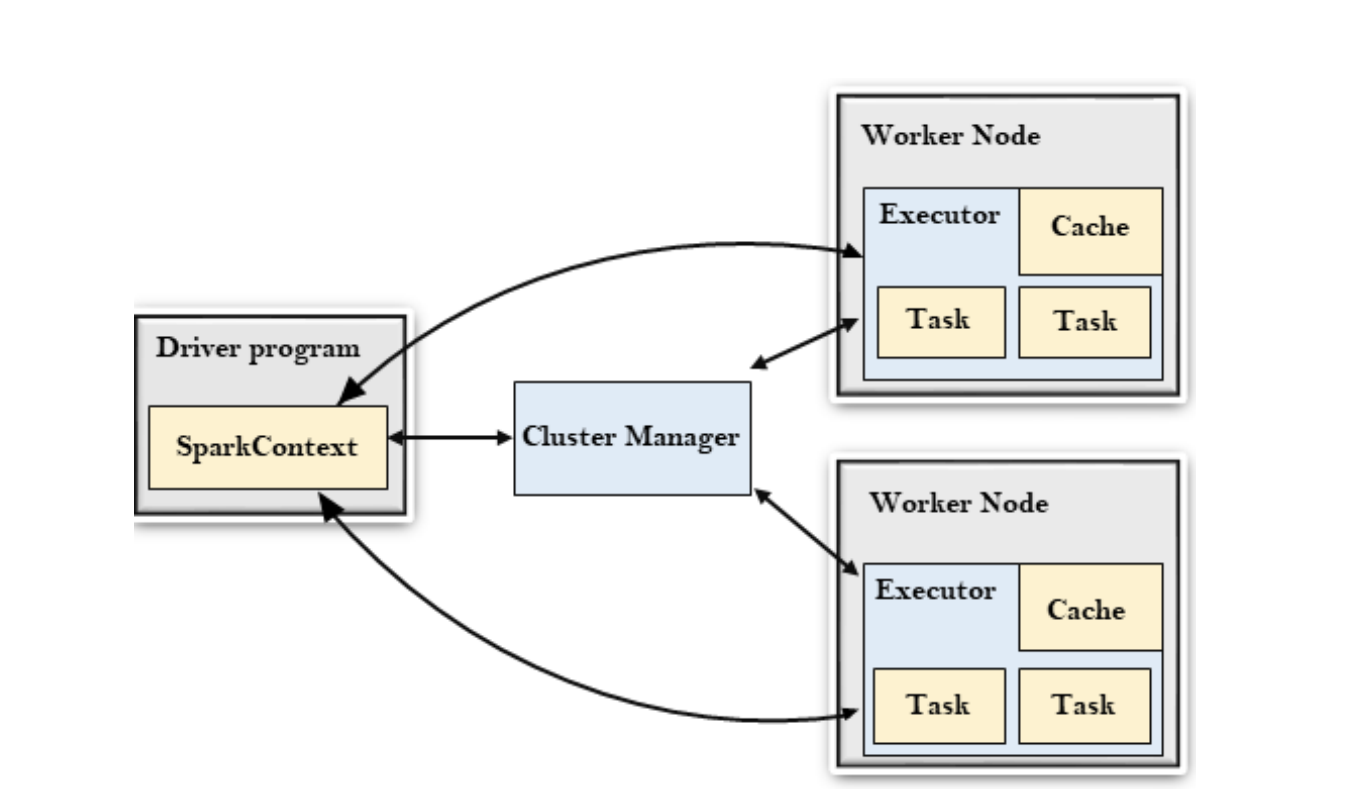
- Driver : Spark Application의 시작점
- Cluster Manager : Yarn, Mesos, K8s 같은 자원 관리 매니저
- Worker Node : 실제 작업이 실행되는 환경
1.2 스파크 작업 흐름
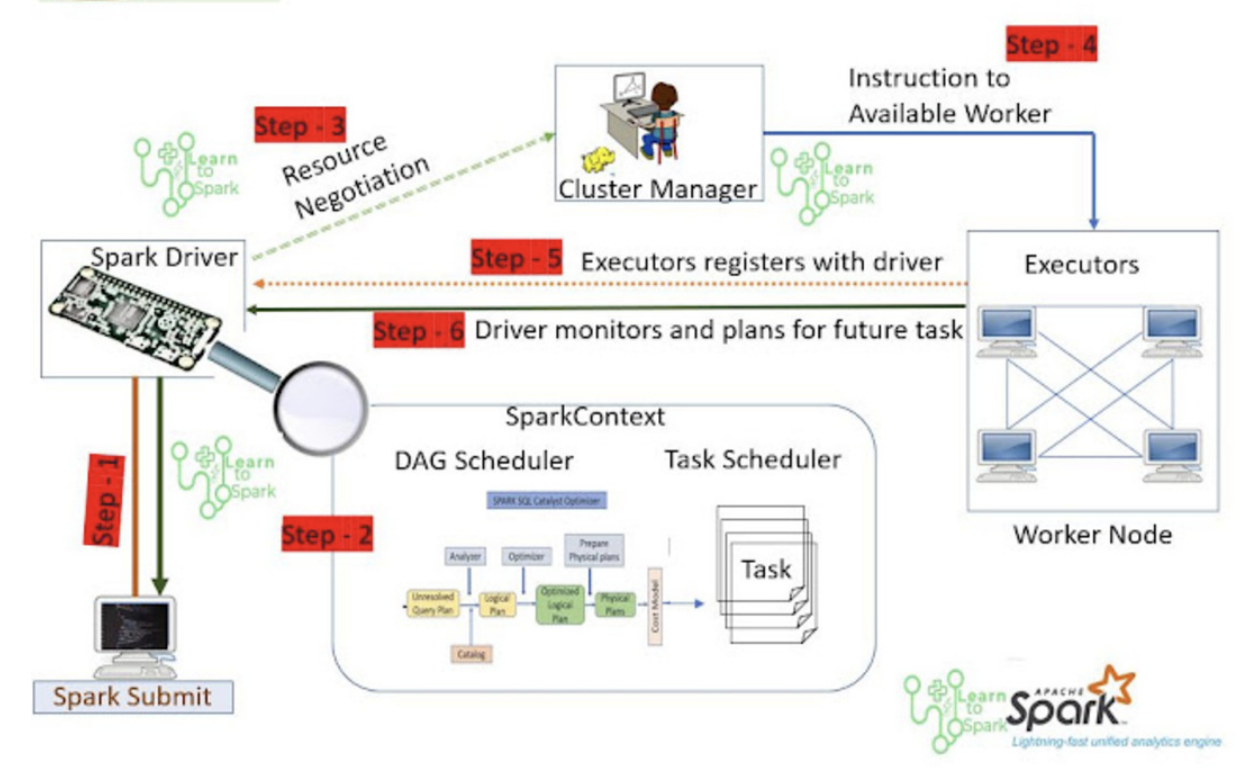
- Spark Driver는 Spark 프로그램의 중앙 처리장치입니다. Spark Context를 시작하고, 제출된 어플리케이션의 실행을 담당합니다.
- 어플리케이션의 실행은 코드 내용을 보고 job의 순서(DAG 형식)로 나눕니다. 각 job은 stage로 나누고, 각 stage는 작은 task 단위로 나뉘게됩니다. task는 task scheduler로 전달됩니다.
- Spark Application code가 submit되면, driver는 코드를 분석한뒤 Cluster manager와 상호작용해서 task를 수행할 리소스를 얻습니다.
- cluster manager는 spark driver가 요청한 리소스를 할당하고, driver가 요청한 프로그램을 worker node에서 실행할 수 있는 instruction을 제공합니다. ClusterManager는 executor의 자원사용, 성능을 트래킹하고, job이 끝나면 driver에게 작업 종료를 알립니다. 작업 실패 시 다른 노드에 할당하는 failover기능도 합니다.
- Executor는 실제 데이터에 접근해 할당된 task를 수행하는 worker입니다. spark job을 submit할때 executor의 수를 지정할 수 있고, Cluster Manager의 허용치 안에서 dynamic 하게 allocation할 수도 있습니다. 수행 결과는 driver에게 전달됩니다.
2. 스파크 사용시 주의할 점
위에 설명한 아키텍처의 구조적인 제약에 따라 스파크 사용시 주의할 사항이 몇가지 있습니다.
2.1 Driver SPOF(단일 장애 지점)
- Client-mode의 경우
Spark Driver는 하나의 JVM이고, executor는 cluster manager와 driver에 의해서 fault-tolerance가 보장되만 Driver는 그렇지 않습니다. 각 executor가 수행하는 task의 결과가 Driver에 모이므로 task의 결과 값 데이터가 큰 경우 Driver가 오버헤드(Out of Memory)로 죽는 경우가 발생할 수 있습니다. 이때 Driver를 자동으로 살려주는 방법이 없어 Driver 프로세스를 모니터링하고 Driver에 문제가 생길경우 대처할 방법이 필요합니다. - Cluster-mode의 경우
cluster-mode의 경우 Spark Driver가 뜬 container가 죽으면 (기본적으로) Driver가 다시 시작합니다. 이때 그 과정에서 executor들이 전달한 데이터가 유지된다는 보장이 없습니다. 이때도 역시 Driver가 SPOF인 것은 변함이 없고 재시작에 대한 고려를 해야합니다.
2.2 Executor의 수와 리소스
- executor의 수를 늘릴수록 parallelism이 증가합니다. executor의 수가 증가하면 in-memory에 의한 병렬연산 속도가 빨라지는 것을 기대할 수 있습니다.(memory양, CPU core 수를 늘린다고 속도가 빨리지진 않음) 다만 데이터의 양 대비 많은 executor를 사용하면 불필요하게 network를 사용하게 될 수 있습니다. 또한 executor의 수가 많아지면 shuffle에서 이동하는 데이터가 많아지므로 오히려 전체 수행시간이 느려지고 시스템 부하는 높아질 수도 있습니다.
2.3 Idempotent(멱등성)
- 작업 실패 시 처음부터 재처리한다.
Executor는 Cluster Manager와 Driver에 의해서 언제든 재시작될 수 있습니다. Driver도 SPOF이기 때문에 fast-fail 전략을 쓴다면 프로그램을 처음부터 다시 시작하는 경우가 꽤 발생합니다. 따라서 Spark Job은 언제든 재처리할 수 있다는 것을 가정하고 작성하는 것이 좋습니다. 하나의 작업을 idempotent하게 작성해야 실제 데이터가 오염되거나 잘못처리되는 일이 없습니다. - Steaming 데이터 처리는 중복처리 주의하기
Batch로 Spark를 사용하는 것과 달리 context가 필요한 streaming 작업의 경우는 context가 필요한 경우가 많기 때문에, 시스템 설계에서부터 at least once, at most once, exactly once를 고려해야 합니다. checkpoint 기능을 잘 활용해서 context를 잘 유지하는 방법을 쓰는 것이 좋습니다. checkpoint를 쓰더라도 streaming application 역시 최대한 idmempotent하게 만드는 게 좋습니다.
'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] 스파크 Window 로컬 환경 설치하기 (0) | 2025.05.26 |
|---|---|
| [Spark] 스파크 RDD란? (Resilient Distributed Dataset) - 2 (0) | 2025.05.26 |
| [Spark] 스파크 RDD란? (Resilient Distributed Dataset) - 1 (1) | 2025.05.26 |
| [Spark] 스파크의 특징과 기본 개념 - 1 (0) | 2025.05.17 |
| [Spark] Spark SQL, DataFrame, Datasets (Structured Data) (0) | 2022.06.21 |