

1. 스파크란
아파치 스파크(apache spark)는 2011년 버클리 대학의 AMPlam에서 개발되어 현재는 아파치 재단의 오픈소스로 관리되고 있는 인메모리 기반의 대용량 데이터 고속 처리 엔진으로 범용 분산 클러스터 컴퓨팅 프레임워크 입니다.
2. 특징
- Speed : 인메모리(In-Memory) 기반의 빠른 처리
- Ease of Use : 다양한 언어 지원(Java, Scala, Python, R, SQL)을 통한 사용의 편이성
- Generality : SQL, Streaming, 머신러닝, 그래프 연산 등 다양한 컴포턴트 제공
- Run Everywhere : YARN, Mesos, Kubernetes등 다양한 클러스터에서 동작 가능
- HDFS, Casandra, HBase 등 다양한 파일 포맷 지원
해당 특징에 대해 자세히 알아보겠습니다.
- 인메모리 기반의 빠른 처리
스파크는 인메모리 기반의 처리로 맵리듀스 작업처리에 비해 디스크는 10배, 메모리 작업은 100배 빠른 속도를 가지고 있습니다. 맵리듀스는 작업의 중간 결과를 디스크에 쓰기 때문에 IO로 인하여 작업 속도에 제약이 생깁니다. 스파크는 메모리에 중간 결과를 저장하여 반복 작업의 처리 효율이 높습니다. - 다양한 언어 지원
스파크는 Java, Scala, Python, R 인터페이스등 다양한 언어를 지원하여 개발자에게 작업의 편의성을 제공합니다. 하지만 언어마다 처리하는 속도가 다릅니다. 따라사 성능을 위해서는 Scala로 개발을 진행하는 것이 좋습니다. - 다양한 컴포넌트 제공
스파크는 단일 시스템 내에서 스파크 스트리밍을 이용한 스트림 처리, 스파크 SQL을 이용한 SQL 처리, MLib를 이용한 머신러닝 처리, GraphX를 이용한 그래프 프로세싱을 지원합니다. 추가적인 소프츠웨어의 설치 없이도 다양한 애플리케이션을 구현할 수 있고, 각 컴포넌트간의 연계를 이용한 애플리케이션의 생성도 쉽게 구현할 수 있습니다. - 다양한 클러스터 매니저 지원
클러스터 매니저로 YARN, Mesos, Kubernetes, standalone등 다양한 포맷을 지원하여 운영 시스템 선택에 다양성을 제공합니다. 또한, HDFS, Cassandra, HBase, S3등의 다양한 데이터 포맷을 지원하여 여러 시스템에 적용이 가능합니다. - 다양한 파일 포맷 지원 및 Hbase, Hive등과 연동 가능
스파크는 기본적으로 TXT, Json, ORC, Parquet등의 파일 포맷을 지원합니다. S3, HDFS등의 파일 시스템과 연동도 가능하고, Hbase, Hive와도 간단하게 연동할 수 있습니다.
3. 스파크가 풀고자 하는 문제
- MapReduce의 한계 극복
대용량 데이터 처리 작업은 MapReduce라는 모델이 효율적이고 강력하다 하여 사용되고 있었습니다. Hadoop Mapreduce 이전에는 처리할 수 없던 대량의 데이터를 처리할 수 있게 해주었지만 빈번한 자원의 할당과 해제의 문제(성능 문제), 중간 결과 파일을 외부 스토리지를 사용함으로서 발생하는 지연시간과 부하 문제, 과도한 shuffle 문제 등으로 인해 실제 데이터 처리 작업보다 부가적인 작업에 의해 시간과 자원을 너무 소모한다는 문제가 있었습니다.
Spark는 분산 데이터 모델인 RDD와 In-memory cache의 활용으로 Hadoop MapReduce의 한계를 대부분 해결했고, 그 결과 Hadoop MapReduce보다 100배 이상의 빠른 성능을 보였습니다. - API로 정형화된 데이터 처리 모델
MapReduce를 토대로 데이터를 처리하는 과정을 정형화될 수 있었습니다. 데이터를 변환하는 것은 map function, 데이터를 걸러내는 것은 filter function, 데이터를 재배치하는 것은 group by, 데이터를 집계하는 것은 reduce/aggregate function 이런식입니다
Spark는 scala 기반의 functional programming의 type 안정성과 완결성을 토대로 데이터 처리모델을 API로 정형화 시켰습니다. API를 통해 기존의 데이터 처리 작업을 작성하는 것보다 코드를 작성하는 것이 쉬워질 뿐만 아니라, 이 토대 하에서 데이터 처리작업을 코드수준에서 무결성을 보장해서 전체적인 개발 생산성을 높일 수 있었습니다. - Multi Language로 확장성
- 더 쉽고 넓은 사용성
Spark Rdd로 분산 데이터 모델을 빠르고 안정적으로 사용할 수 있게 만들고, Spark의 API로 데이터 처리작업에 대한 정형화를 이루었습니다. Spark API를 몰라도 ANSI SQL만으로도 대용량 처리작업에 대해서 Spark로 처리가 가능하게 만들었습니다. 또한 복잡한 ML 연산을 쉽게 제공하도록 MLib 라이브러리로 대용량 데이터에 대해 빠른 ML연산이 가능하게 만들었습니다.
4. 컴포넌트 구성
스파크 컴포넌트 구성은 스파크 라이브러리, 스파크 코어, 클러스터 매니저로 구분되어 있습니다.
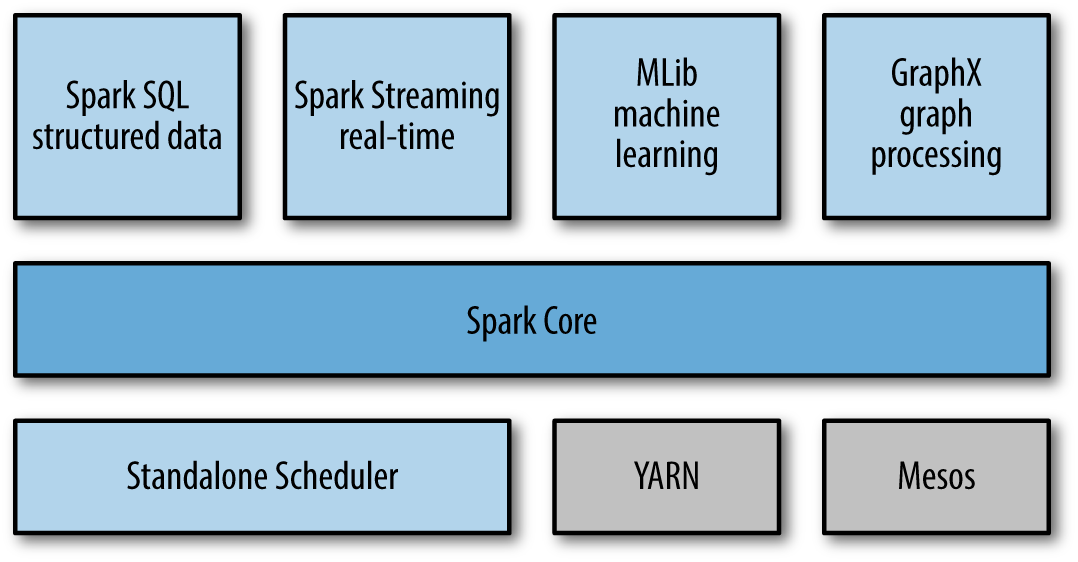
- Spark Core
메인 컴포넌트로 작업 스케줄링, 메모리 관리, 장애 복구와 같은 기본적인 기능을 제공하고, RDD, Dataset, DataFrame을 이용한 스파크 연산을 처리합니다. - Spark Streaming
스파크 스트리밍은 실시간 데이터 스트림을 처리하는 컴포넌트입니다. 스트림 데이터를 작은 사이즈로 쪼개어 RDD API와 비슷한 데이터 스트림 조작 API를 이용해 처리합니다. 데이터 스트림이란 웹 서버에서 생성한 로그 파일, 사용자들이 만들어내는 상태 업데이트 메세지들이 저장되는 큐 등이 해당됩니다. 스파크 스트리밍은 스파크 코어와 동일한 수준의 장애 관리, 처리량, 확장성을 지원하도록 설계 되어있습니다. - MLib
스파크 기반의 머신러닝 기능을 제공하는 컴포넌트입니다. 분류, 회귀, 클러스터링, 협업 필터링 등의 다양한 타입의 머신 러닝이 알고리즘 뿐만 아니라 모델 평가 및 외부데이터 불러오기 같은 기능도 지원합니다. 그리고 경사 하강 최적화 알고리즘 같은 몇몇 저수준의 ML 핵심 기능들도 지원합니다. 이 모든 기능들은 클러스터 전체를 사용하며 실행되도록 설계되었습니다. - GraphX
분산형(병렬 연산) 그래프 프로세싱이 가능하게 해주는 컴포넌트입니다. 각 간선이나 점에 임의의 속성을 추가한 지향성 그래프를 만들 수 있습니다. Spark Streaming이나 SparkSQL처럼 GraphX도 Spark RDD API를 확장하였습니다. 또한 그래프를 다루는 다양한 메소드들 및 일반적인 그래프 알고리즘들의 라브러리를 지원합니다. - Cluster Manager
스파크 작업을 운영하는 클러스터 관리자 입니다. 스파크는 한 노드에서 수천 노드까지 효과적으로 성능을 확장할 수 있도록 만들어졌습니다. 유연성을 극대화하면서 이를 달성하기 위해 스파크는 Standalone, YARN(hadoop), Mesos(Apache) 등 다양한 클러스터 매니저 위에서 동작할 수 있습니다.
5. 스파크의 기본 구조
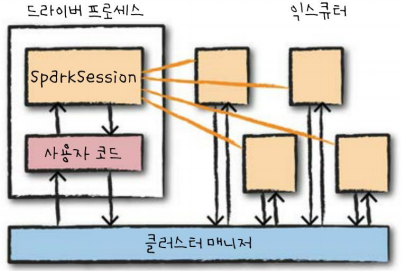
스파크 애플리케이션은 Master-Slave 구조로 실행됩니다. 사용자가 클러스터 매너지에 스파크 애플리케이션을 제출하고, 클러스터 매니저로부터 받은 자원을 이용하여 작업을 처리합니다. 이때, 드라이버와 익스큐터는 단순한 프로세스이므로 같은 머신 또는 다른 머신에서 실행이 가능합니다.
- 드라이버 프로세스 - Master
스파크 응용을 위한 SparkSession을 관리하는 JVM 프로세스로 DAG(Directed Acyclic Graph)기반 테스크 스케줄링을 수행합니다. 사용자 프로그램을 테스크라고 불리는 실제 수행 단위로 변환하고, 익스큐터 프로세스의 작업과 관련된 분석 및 관리를 담당합니다. - 익스큐터 - Slave
마스터인 드라이버 프로세스가 할당한 작업을 수행 및 결과를 반환하며, YARN의 컨테이너와 유사합니다.
'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] 스파크 Window 로컬 환경 설치하기 (0) | 2025.05.26 |
|---|---|
| [Spark] 스파크 RDD란? (Resilient Distributed Dataset) - 2 (0) | 2025.05.26 |
| [Spark] 스파크 RDD란? (Resilient Distributed Dataset) - 1 (1) | 2025.05.26 |
| [Spark] 스파크의 특징과 기본 개념 - 2 (0) | 2025.05.17 |
| [Spark] Spark SQL, DataFrame, Datasets (Structured Data) (0) | 2022.06.21 |