

1. 아키텍처
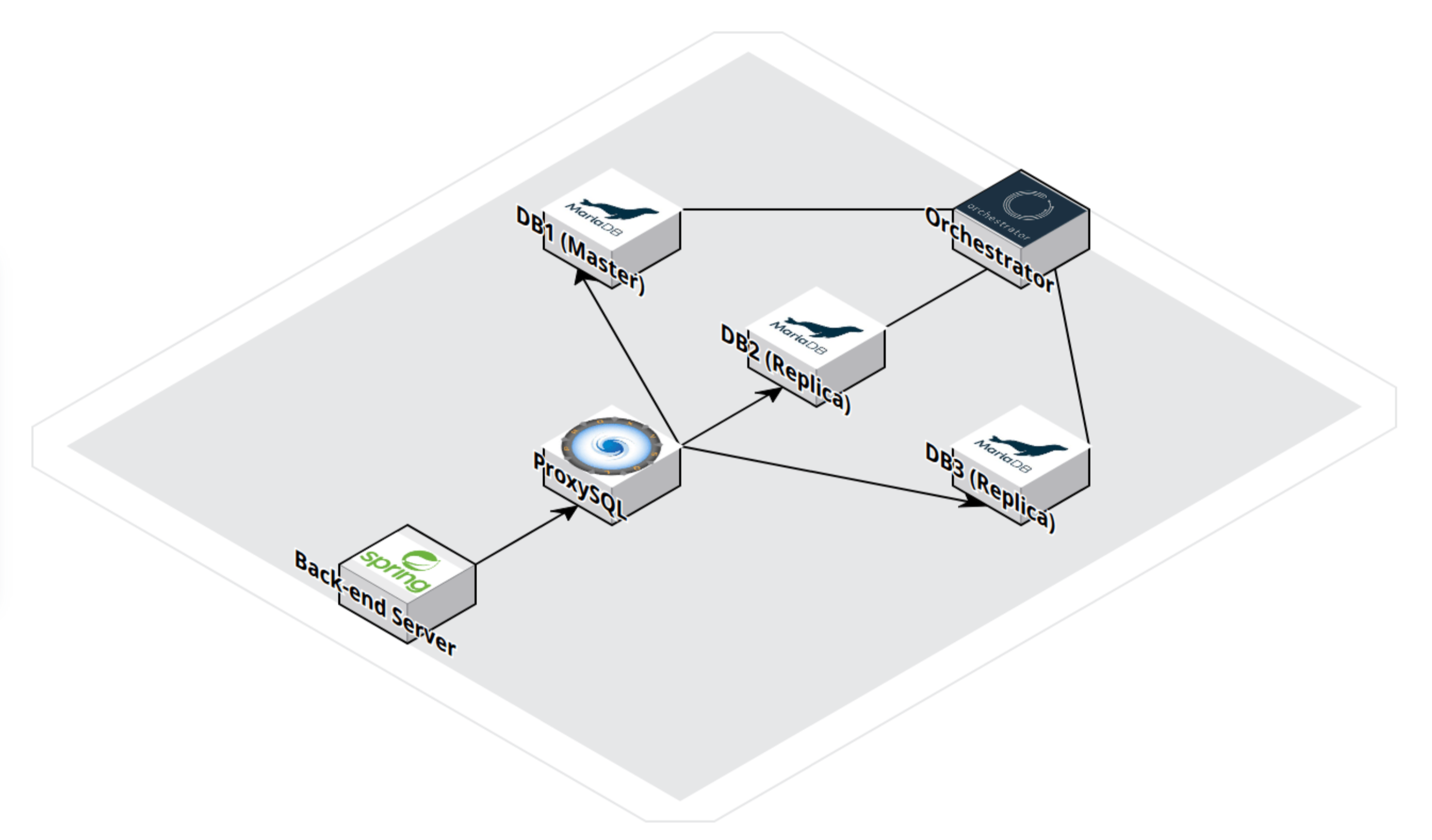
1.1 기본 구조
- 기본적으로 3계층 아키텍쳐(3 Layer Architecture)를 따르며 위의 아키텍처는 Client-APP-Data layer중 Data Layer를 집중적으로 다루었습니다.
- VMware을 이용해 DB Server 3대, Porxy SQL Server 1대, Orchestrator Server 1대로 총 5대의 VM으로 Data layer을 구축했습니다.
- K8s같은 오케스트레이션 플랫폼을 사용하는게 아닌 VMware와 Mysql Orchestrator만 사용되므로 자동으로 VM이 생성하거나 삭제하는 작업이 어려워 최대한 초기에 구성된 VM을 사용해 고가용성을 만족하도록 구성했습니다.
1.2 App Server
- Spring을 사용한 App server를 구축했습니다.
- DB에 읽기 / 쓰기 요청을 보냅니다. (실제 구성에서는 2대의 APP server가 있습니다.)
1.3 DB
- DB는 무료로 사용할 수 있는 Maria DB를 사용했습니다.
- 고가용성을 위해 1대의 Master와 2대의 Replica를 구성했습니다.
- Master - Replica 복제 방식은 GTID(Global Transaction ID)를 사용해 복제하도록 설정했습니다.
1.4 ProxySQL
- App server에서 요청되는 읽기 / 쓰기 부하를 분산하기 위해 사용했습니다.
- Master는 쓰기 작업, Replica는 읽기 작업을 하도록 경로를 설정했습니다.
- ProxySQL의 설정을 통해 App Server에서 SELECT 요청이 오면 Replica, INSERT/DELETE/UPDATE 요청이 오면 Master로 처리될 수 있도록 합니다.
- 모니터링을 통해 Master(쓰기 서버)가 Fail이 감지되면 자동으로 Replica(읽기 서버)를 쓰기 요청이 되도록 변경됩니다.
1.5 Orchestrator
- MySQL Orchestrator를 사용해 3대의 DB Server를 모니터링하고 Fail을 감지하도록 했습니다.
- DB Fail 시 자동으로 Failover(장애조치)가 되도록 했습니다.
- Master DB Fail 시 특정 Replica를 Master로 승격(Read only 설정 변경 및 Master - Replica 연결 재설정)하고 Porxy SQL은 Read only설정이 변경되면 자동으로 감지해서 읽기/쓰기 경로를 변경해줍니다.
2. DB 복제
2.1 Bin log vs GTID
DB 복제 방법은 일반적으로 Bin log와 GTID 복제방식이 있습니다. 저는 고가용성 환경을 위해 GTID사용하는 복제 방식을 채택했는데 두 복제 방식을 비교해보고 왜 고가용성 환경에 GTID 복제 방식이 유리한지 알아보겠습니다.
- Bin log 복제
- Master 서버에서 발생한 모든 변경 작업(INSERT, UPDATE, DELETE)을 binlog 파일에 기록하는데 Slave 서버가 이 로그를 읽고 똑같은 작업을 수행
- 서버 간의 명시적인 위치(Position)를 기준으로 복제 진행
- 장점
- 오래된 버전에서도 사용 가능
- 설정이 비교적 단순함
- 단점
- 복제 위치(Position)를 수동으로 관리해야 함
- Failover 시 복잡 (어느 위치까지 처리됐는지 추적 필요)
- 여러 Master 또는 Circular 복제에는 부적합
- GTID 복제
- 트랜잭션마다 고유한 UUID 기반의 식별자(GTID)가 부여되며 Slave는 GTID를 기반으로 어떤 트랜잭션이 이미 처리됐는지 자동으로 판단함
- 장점
- 자동 포지셔닝: 복제 지점 추적 불필요
- 장애 조치(Failover)가 쉬움 > 자동화 도구(MHA, Orchestrator 등)와 궁합이 좋음
- 여러 Slave / Master간 충돌 방지에 유리
- 단점
- 모든 서버에서 GTID 설정 및 일관성 유지 필요
- 복잡한 복제 구조에서 conflict 해결이 어려울 수 있음
- 마이그레이션 시 호환성 이슈 발생 가능
2.2 구성 방법
https://www.notion.so/DB-Replica-GTID-1e3d702ab8e180d6981ddfcfcdbb1ca9?pvs=4
고가용성 DB Replica(GTID) 셋팅 | Notion
MariaDB 설치 및 셋팅
www.notion.so
3. 부하 분산
일반적인 Web Service용 DB는 쓰기 작업보다 읽기 작업이 많이 발생합니다. 이러한 시스템에서 부하를 줄이기 위해 ProxySQL을 사용하였는데 ProxySQL이 무엇이고 어떻게 부하 분산을 했는지 설명드리겠습니다.
3.1 ProxySQL 부하 분산

- ProxySQL 이란?
- ProxySQL은 MySQL 및 MariaDB용 고성능 SQL프록시 서버입니다.
- 일반적으로 DB 클러스터 앞단에 위치해 SQL트래픽을 중개하고 관리함으로써, 고가용성(HA), 로드 밸런싱, 쿼리 라우팅, 캐싱, 장애 조치(Failover) 등의 기능을 제공합니다.
- ProxySQL 부하 분산 셋팅
- ProxySQL은 App Server의 SQL 요청을 받고 설정된 DB 경로에 SQL 작업을 하게 합니다.
- 초기 설정으로 Master DB는 쓰기 작업, Replica DB는 읽기 작업을 처리하도록 경로를 설정했습니다.
- 모니터링
- 모니터링 모드를 사용해 읽기 / 쓰기 DB가 정상적으로 작동 중인지 확인하도록 했습니다.
- 문제가 발생한 경우 Orchetrator에 의해 설정이 변경되며 변경된 설정을 ProxySQL이 탐지해 자동으로 경로가 변경이 됩니다.
3.2 구성방법
https://www.notion.so/ProxySQL-1dfd702ab8e180e5bc1ecffff2897fb5?pvs=4
ProxySQL | Notion
ProxySQL 설치
www.notion.so
4. Orchestrator를 활용한 장애조치(Failover)
고가용성 환경을 위해서는 DB Fail 시 시스템 중단 없이 자동으로 장애조치(Failover)를 할 수 있어야 합니다. 그러한 작업을 해주는 Orchestrator에 대해 알아보고 어떻게 작동이 되는지 알아봅시다.
4.1 MySQL Orchestrator

- MySQL Orchestrator란?
- MySQL Orchestrator는 GitHub(github.com/openark/orchestrator) 에서 오픈소스로 제공되는 MySQL/MariaDB 복제 토폴로지 관리 및 장애 조치(Failover) 자동화 도구입니다. 대규모 복제 환경에서 토폴로지 변화를 시각화하고, 안정적인 장애 복구를 지원하며, 운영자가 최소한의 개입으로 복제 구조를 관리할 수 있도록 도와줍니다.
- 웹 UI를 사용할 수 있어 운영 편의성을 제공합니다.
- 주요 기능
- 토폴로지 시각화 & 탐색
- 복제 트리(Topology)를 그래프 형태로 보여주어 Master-Slave관계 및 복제 경로를 한눈에 파악
- 자동 장애 감지 & 장애 조치(Failover)
- 사전 정의된 조건(연속된 Ping 실패, binLog) 지연 등)으로 Replica 장애를 감지
- 장애 발생 시 즉시 최적의 승격(Candidate Promotion) 대상 Replica를 선정하여 Master로 승격
- 이전 Master와의 분리(Isolate) 및 새로운 Replica들과의 재연결(Re-replication) 자동 수행
- 토폴로지 변경 관리
- Replica 추가/제거, Master 변경 등 토폴로지 변경 절차를 CLI나 API 호출로 자동화
- Planned Maintenance 모드 제공: 점검 중인 인스턴스를 안전하게 제거 후 복귀
- 데이터 안정성 보장
- GTID 기반 복제뿐 아니라 binlog position 기반 복제 지원
- Promotion 시각에 가장 최신의 트랜잭션을 가진 Replica를 승격하여 데이터 유실 최소화
- 운영 편의성
- SMTP/Slack/PagerDuty 등 다양한 알림 채널 연동
- Role-based Access Control(RBAC)으로 사용자별 권한 관리
- Ansible, Terraform 등 IaC 도구와 연동하여 인프라 프로비저닝 자동화
- 토폴로지 시각화 & 탐색
4.2 장애 조치(Failover)
Orchestrator는 다양한 설정에 맞춰 장애조치를 하게됩니다. 대표적으로 Master 장애 시 자동 복구 과정이 어떻게 진행되는지 알아봅시다.
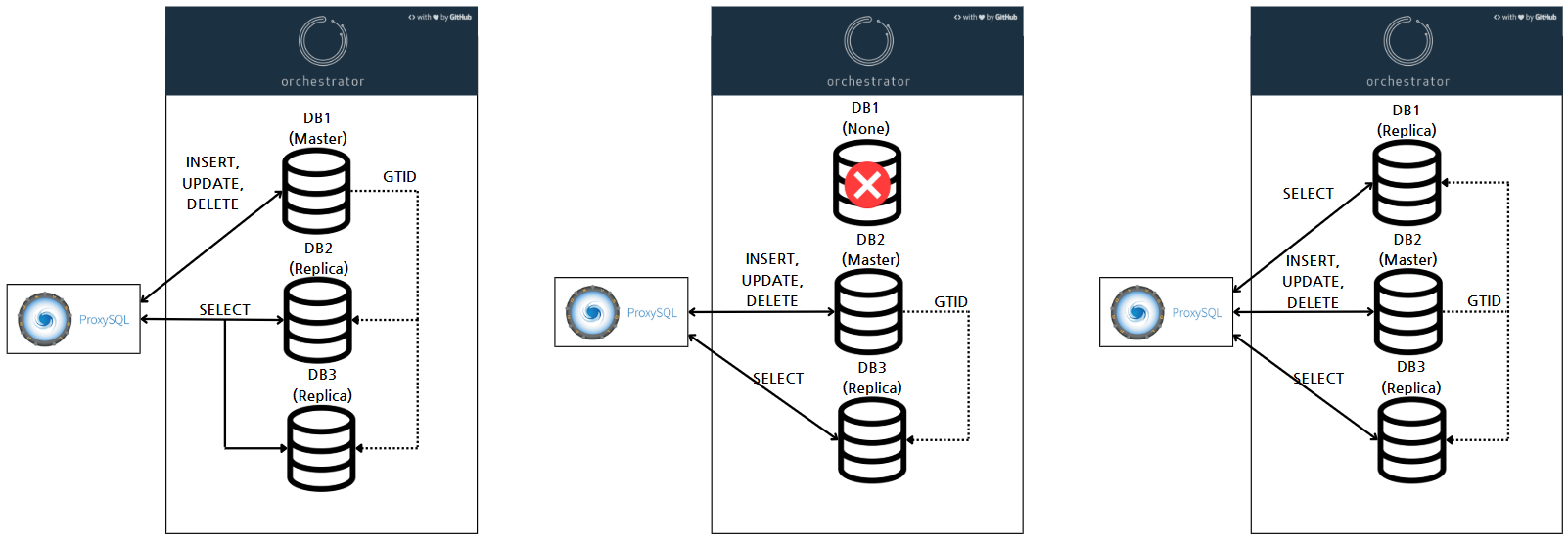
- 장애 발생 시 Master 변경
Master DB에 Fail에 발생 시 Orchestrator는 Replica 중 하나를 Master로 승격시킵니다. 승격된 Replica의 Read only설정을 변경하고 다른 Replica와 재 연결(re-replication) 작업을 합니다. - Fail된 DB 복구
작업자는 수동으로 Fail DB의 장애 상황을 해결한 후 Replica를 다시 연결 해주면 초기에 구성된 환경으로 복구할 수 있습니다.
4.3 구성 방법
https://www.notion.so/Orchestrator-1e3d702ab8e18080b58cfd3401fa6be9?pvs=4
Orchestrator 셋팅 | Notion
Orchestrator 설치
www.notion.so
5. 후기
On premise 환경에서 고가용성 DB환경을 직접 구축해보면서 DB Replica 구성 방식과 ProxySQL, MySQL Orchestrator 사용 이유를 알 수 있었던 유익한 시간이었습니다. 고가용성 DB 환경을 구축해도 ProxySQL, Orchestrator은 단일 서버다 보니 해당 Server가 죽으면 시스템이 동작을 멈추는 SPOF 문제가 있어서 해당 문제를 어떻게 해결할지가 숙제가 될 것 같습니다.
이것저것 테스트하고 관련 레퍼런스를 찾는데 생각보다 시간이 소요되서 구축하는데 2~3일이 시간이 걸렸습니다. 왜 돈을 들여가며 클라우드 서비스를 사용하는지 다시 한번 깨달았습니다.
그리고 아직 K8s같은 오케스트레이션 플랫폼 학습이 부족해 사용하지 못해서 아쉬웠습니다. K8s 학습 후 docker를 활용한 on-premise 고가용성 DB 환경을 구축해보면서 이번에 작업한 내용과 비교해 보는 시간을 가져보겠습니다.
'Data Engineering > DB' 카테고리의 다른 글
| [RDB] RDBMS란 (2) | 2023.02.18 |
|---|