

안녕하세요! 최근 Airflow Helm Chart를 사용하여 GKE(Google Kubernetes Engine)에 Airflow를 배포하면서 겪었던 흥미로운 문제 해결 과정을 공유하려고 합니다. 배포 과정에서 airflow-api-server Pod가 계속해서 CrashLoopBackOff 상태에 빠지는 문제가 발생했는데요. 해당 문제를 해결해 가는 과정을 단계별로 정리했습니다.
문제: Pod의 무한 재시작
kubectl get po 명령어를 실행했을 때, airflow-api-server Pod의 STATUS가 Running으로 표시되지만 READY 상태가 0/1이고, RESTARTS 카운트가 계속 올라가는 현상이 발생했습니다. 이는 Pod 내부의 컨테이너가 정상적으로 시작되지 못하고 계속 충돌하고 있다는 신호였습니다.

kubectl logs -f 명령어로 로그를 확인해보니, Uvicorn 프로세스는 시작되지만 곧바로 Child process died라는 메시지가 반복적으로 나타나고, 결국 Pod가 SIGTERM 신호를 받아 종료되는 패턴이 반복되었습니다.

가설 1. Airflow Secret 또는 설정 문제
가장 먼저 의심했던 것은 Airflow의 필수 설정인 Secret과 values.yaml 파일의 오류였습니다. Airflow는 fernetKey, apiSecretKey와 같은 중요한 정보를 Secret으로 관리하는데, 이 값이 잘못되었을 경우 Pod가 제대로 초기화되지 않을 수 있습니다.
시도한 것들:
- fernetKey Secret 확인: values.yaml에 Base64로 인코딩된 fernetKey 값이 올바르게 설정되었는지, 혹은 Secret이 정상적으로 생성되었는지 확인했습니다.
- 다른 설정값 검토: values.yaml 파일 전체를 꼼꼼히 검토하여 다른 설정값에 오타나 잘못된 부분이 없는지 확인했습니다.
- airflow.cfg 확인: ConfigMap으로 생성된 airflow.cfg의 내용을 kubectl get configmap 명령어로 직접 확인하여 설정이 제대로 반영되었는지 검증했습니다.
결과: 모든 설정값과 Secret은 정상적으로 보였고, 문제 해결에 도움이 되지 않았습니다.
가설 2: 메타데이터 DB 연결 오류
다음으로 Airflow의 핵심인 메타데이터 데이터베이스(DB) 연결에 문제가 있을 수 있다고 가정했습니다. Airflow는 시작 시 메타데이터 DB에 연결하여 스키마를 마이그레이션하고 필요한 정보를 로드합니다. DB 연결이 실패하면 애플리케이션 자체가 시작되지 못하고 충돌할 가능성이 큽니다.
시도한 것들:
- values.yaml의 DB 정보 확인: PostgreSQL DB의 host, port, user, pass 값이 정확한지 확인했습니다. GCP Cloud SQL을 사용하고 있었는데, IP 주소나 포트 정보가 올바르게 입력되었는지 재차 검토했습니다.
- 임시 디버그 Pod로 연결 테스트: kubectl run 명령어를 사용해 Airflow Pod와 동일한 네트워크 환경에 임시 Pod를 생성했습니다. 이 Pod에서 psql 클라이언트를 실행하여 Cloud SQL DB에 직접 연결을 시도했습니다.
kubectl run -it --rm --restart=Never debug-pod --image=postgres:13-alpine --namespace airflow -- sh psql -h [DB_HOST] -p [DB_PORT] -U [DB_USER] -d [DB_NAME] - Cloud SQL 방화벽 규칙 확인: GCP 콘솔에서 Cloud SQL 인스턴스의 '승인된 네트워크' 설정을 확인했습니다. GKE 클러스터 노드의 IP 대역(10.0.0.0/8 등)이 DB 방화벽 규칙에서 허용되어 있는지 확인했습니다. 또한, 0.0.0.0/0을 승인된 네트워크에 추가하여 모든 IP에서의 접속을 허용하는 테스트도 진행했습니다.
결과:
- 방화벽 문제 해결: Cloud SQL에 방화벽 규칙 설정이 안된 문제와 클러스터 재부팅 시 public ip가 변동되는 자잘한 문제가 있었지만 재설정 후 정상적으로 DB 연동 확인했습니다. 하지만 CrashLoopBackOFF는 계속 발생했습니다.
- DB 연동 문제는 근본적인 원인이 아님: 임시 Pod를 통한 DB 연결 테스트는 성공했습니다. 이는 Pod와 DB 간의 네트워크 연결 자체에는 문제가 없다는 것을 의미하며, DB 연결 오류가 CrashLoopBackOFF 발생의 근본적 원인이 아니었습니다.
가설 3: 리소스 부족 (CPU/메모리)
남은 가능성은 Kubernetes 노드의 리소스 제약이었습니다. Airflow API 서버는 초기 시작 시 상당한 CPU와 메모리를 요구할 수 있습니다. 만약 Pod가 배포된 노드에 충분한 리소스가 없다면, 컨테이너가 충돌할 수 있습니다.
시도한 것들:
- 노드 CPU 사용량 확인: GCP 콘솔의 GKE 모니터링 페이지에서 클러스터의 노드 CPU 사용량을 확인했습니다. 특정 노드의 CPU 사용량이 147.9%에 달하는 것을 발견했습니다. 이는 노드가 이미 과부하 상태이며, 새로운 Pod가 리소스를 할당받기 어려움을 보여주는 강력한 증거였습니다.

- values.yaml 리소스 설정 조정: 과도하게 자원을 사용하는 것을 의심 해서 airflow-api-server의 values.yaml에 설정된 resources.limits 및 requests 값을 적절한 값으로 설정했습니다.
- 클러스터 노드 사양 업그레이드: GKE 클러스터의 노드 풀을 e2-medium (2 vCPU, 4GB메모리)에서 e2-standard-4 (4 vCPU, 16GB 메모리)로 사양을 업그레이드했습니다.
결과:
- 리소스 사용량 제한 : CPU 사용량을 보고 API 서버가 사용량 설정이 없어 api server가 과도한 자원을 요구하는것을 의심해 values.yaml에 리소스 설정으로 조정을 했지만 문제가 해결되지 않았습니다.
- GKE 클러스터 노드 사양 업그레이드: GKE 클러스터의 CPU 사양을 올리고 확인해 봤지만 문제가 해결되지 않았습니다. 이전에 설정한 리소스 사용량 제한 때문이었습니다. airflow-api-server의 리소스 제한 설정을 제거하자, Pod가 정상적으로 시작되었습니다. CrashLoopBackOff 문제가 해결되었고, 모든 서비스가 Ready 상태로 전환되었습니다.
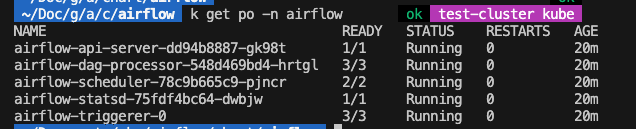
최종 결론: 리소스 부족으로 인한 애플리케이션 충돌
이번 문제의 최종 원인은 리소스 부족이었습니다. Child process died라는 메시지는 Uvicorn이 Airflow API 서버를 실행하는 자식 프로세스를 시작하려 했지만, 노드의 CPU 과부하로 인해 프로세스가 충분한 리소스를 할당받지 못하고 비정상적으로 종료된 것을 의미합니다.
저는 airflow의 기본 사양이 생각보다 높다는 걸 간과해버렸고 위와 같이 고생하게 되었습니다.
(airflow 최소사양 2코어 / 4GB 메모리)
이 경험을 통해 사용할 서비스의 기본사양을 먼저 확인하는 것의 중요성과 kubectl logs에서 보이는 일반적인 경고 메시지 이면에 숨겨진 근본적인 인프라 문제를 찾아내는 것이 얼마나 중요한지 깨달았습니다. Kubernetes 환경에서 애플리케이션 배포 시, 애플리케이션 설정뿐만 아니라 기반 인프라의 리소스 상태를 함께 고려하는 습관을 들여야 겠습니다.
'Data Engineering > Airflow' 카테고리의 다른 글
| [Airflow] Airflow on Kubernetes - Kubernetes에서 Airflow 운영하기 (3) | 2025.08.05 |
|---|