

지난 포스팅에서 이어집니다.
[Project] DE Toy Project - 데이터 수집(네이버 쇼핑 리뷰 크롤링 삽질하기)
1. 프로젝트 주제이번 프로젝트의 목표는 사용자가 검색한 상품에 대한 준 실시간 리뷰 요약 및 감정 분석 시스템을 만드는 것이다.단순한 데이터 분석이 아닌, 실제 웹에서 데이터를 수집하고
tjlog-tistory.tistory.com
이번 포스팅에서는 쿠팡 상품 리뷰를 크롤링하며 겪은 내용과 고민들을 작성했습니다.
1. 프로젝트 목표
이번 프로젝트의 목표는 사용자가 검색한 상품에 대한 준 실시간 리뷰 요약 및 감정 분석 시스템을 만드는 것입니다.
단순한 데이터 분석이 아닌, 실제 웹에서 데이터를 수집하고 처리하는 ETL 흐름까지 구현하고자 했습니다.
2. 데이터 수집 목표
- 준실시간성을 고려한 데이터 ETL 파이프라인 구축
- 높은 속도로 리뷰 데이터를 안정적으로 수집
- Spark로 병렬 처리할 수 있을 정도의 대용량 데이터 확보
3. 수집 대상
- 쿠팡 상품 리뷰를 중심으로 크롤링
(처음에는 네이버 쇼핑도 고려했으나, 접근 차단 이슈로 쿠팡에 집중)
4. 진행 사항 및 기술 선택 흐름
4.1. Playwright 시도
- 첫 요청 시엔 정상적으로 접근되지만, 두 번째 요청부터 바로 차단
- User-Agent 변경, context 초기화 등 우회 시도했지만 지속적 차단
- 결론: Playwright는 쿠팡 리뷰 수집에 부적합
4.2. Selenium (with undetected_chromedriver) 시도
- 수집 Flow: 상품 검색 → 상품 클릭 → 상세 페이지 진입 → 리뷰 수집
❗ 문제 1: 상품 상세 페이지 접근 실패
- 기본 webdriver로는 쿠팡 상세 페이지에서 데이터 처리 오류 발생 (접근 차단)
- undetected_chromedriver 사용 시 정상 접근 확인
❗ 문제 2: 리뷰 탭 클릭 실패
- 리뷰 탭 요소를 찾지 못하는 이슈 발생
- 스크롤 명령어로 동적 요소 로딩을 유도했지만 작동하지 않음
👉 원인:
문제 1에서 브라우저는 새 페이지로 이동했지만 Selenium의 driver 객체는 이전 페이지의 DOM 상태에 머물러 있었던 것
→ 해결: 상품 상세 페이지의 URL을 직접 가져와 driver.get()을 통해 새로 접근하도록 수정
→ 이후 정상적으로 리뷰 영역 탐지 가능
* 추가 발견: 리뷰는 정적 렌더링되어 있어 탭을 누르지 않아도 HTML 상에 이미 존재함. 즉, 애초에 리뷰 탭을 눌러서 리뷰요소를 렌더링 시킬 필요가 없었음
4.3. 리뷰 정보 추출
- 상세페이지별 DOM 구조가 조금씩 달라 XPath 기반 추출은 불안정
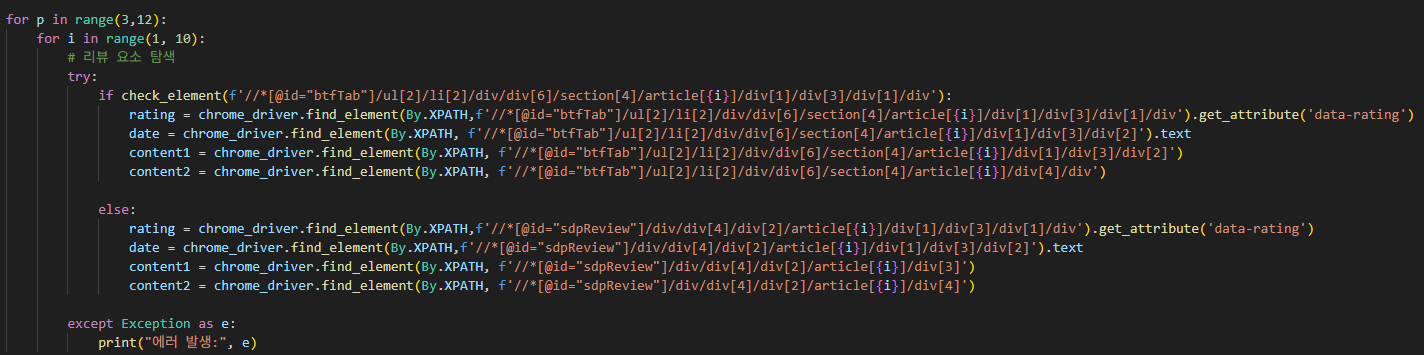
- CSS Selector를 활용한 상대경로 기반 추출로 전환 → 다양한 상품 페이지에서 안정적으로 작동 확인

.text, .get_attribute("data-rating") 등으로 별점, 날짜, 리뷰 본문 추출 완료
4.4. BeautifulSoup 접근 시도
- 정적 렌더링이기 때문에 requests + BeautifulSoup 조합이 더 빠를 것 같아 시도
- 하지만 쿠팡은 Akamai 기반 WAF로 정적 요청 자체를 차단
- 403 또는 Access Denied 페이지 응답
- 결국 Selenium을 그대로 유지하는 것으로 결정
4.5. 리뷰 페이지 넘김 처리
- 숫자 버튼 (1 ~ 10) 클릭을 통해 리뷰 페이지 이동 구현
- 특정 페이지 버튼 클릭 시 ElementClickInterceptedException 발생
→ 해결: scrollIntoView() + offset scroll 및 ActionChains로 클릭 처리 안정화
4.6. 쿠팡 리뷰 크롤링 코드 GitHub Link
DE_Toy_Project/crawling_api/crawling/window_coupang_crawling.py at main · ih-tjpark/DE_Toy_Project
data engineering toy project. Contribute to ih-tjpark/DE_Toy_Project development by creating an account on GitHub.
github.com
5. 앞으로 해야 할 일
5.1 기능 구체화
- 기능 1: 범용 키워드 기반 리뷰 분석
- 예: "청소기"로 검색 → 결과에 나온 모든 상품의 리뷰 수집 및 분석
- 기능 2: 특정 상품 기반 리뷰 분석
- 예: "Teendow 차이슨 V07"으로 검색 → 해당 모델명에 해당하는 리뷰만 필터링 및 분석
5.2 성능 향상
- Selenium 구조 특성상 속도가 느리므로,
- 멀티스레드 또는 멀티프로세싱으로 병렬 수집 구현 필요
(쿠팡 robot.txt에서 기본적으로 크롤링을 금지하고 있기 때문에 너무 많은 요청이 가지않도록 주의)
5.3 대규모 데이터 확보 전략
- 일부 키워드는 리뷰가 적음 → 많이 팔리는 키워드 위주로 크롤링 설계
- 또는 다른 이커머스 플랫폼(지마켓, 11번가 등)에서 데이터 보충 고려
6. 결론 및 후기
이번 크롤링은 단순히 데이터를 수집하는 데 그치지 않고, 브라우저 자동화의 본질적인 문제와 웹사이트의 구조적 차단 장치를 이해하고 우회하는 과정이었습니다.
다음에는 병렬처리로 크롤링 속도를 향상 시키고 수집된 리뷰를 .parquet 포맷으로 저장해 Spark 기반 대규모 텍스트 처리 파이프라인도 구현할 예정입니다.
그 후 리뷰 데이터를 기반으로 감정 분석, 요약 모델 등을 적용해보고자 합니다.
다른 교육과 함께 병행하다 보니 온전히 이 프로젝트에 집중하기 힘들지만 그래도 제가 목표로한 시스템을 구현하기 위해 차근차근 진행해보겠습니다.
'Project' 카테고리의 다른 글
| [Project] DE Toy Project - 팀 프로젝트 회고 및 고도화 계획 (0) | 2025.07.03 |
|---|---|
| [Project] 실시간 쿠팡 리뷰 분석 with Hybrid Cloud (클라우드 아키텍쳐 솔루션 교육과정) (0) | 2025.07.01 |
| [Project] DE Toy Project - 데이터 분석(분석 모델 테스트) (2) | 2025.06.25 |
| [Project] DE Toy Project - 데이터 수집(쿠팡 크롤링과 병렬 처리) 3 (1) | 2025.06.24 |
| [Project] DE Toy Project - 데이터 수집(네이버 쇼핑 리뷰 크롤링 삽질하기) 1 (0) | 2025.05.30 |